The Era of Default Cloud AI is Over
The release of Google’s Gemma 4 signals a definitive architectural shift in enterprise artificial intelligence. While cloud-based Large Language Models (LLMs) like GPT-4 and Gemini Advanced initiated the AI wave, relying exclusively on cloud endpoints is no longer the definitive setup for secure, scalable systems. As detailed in Google’s official release announcement, Gemma 4—an open-weights model available under a commercially permissive Apache 2.0 license—proves that locally hosted models are fully ready for production environments.
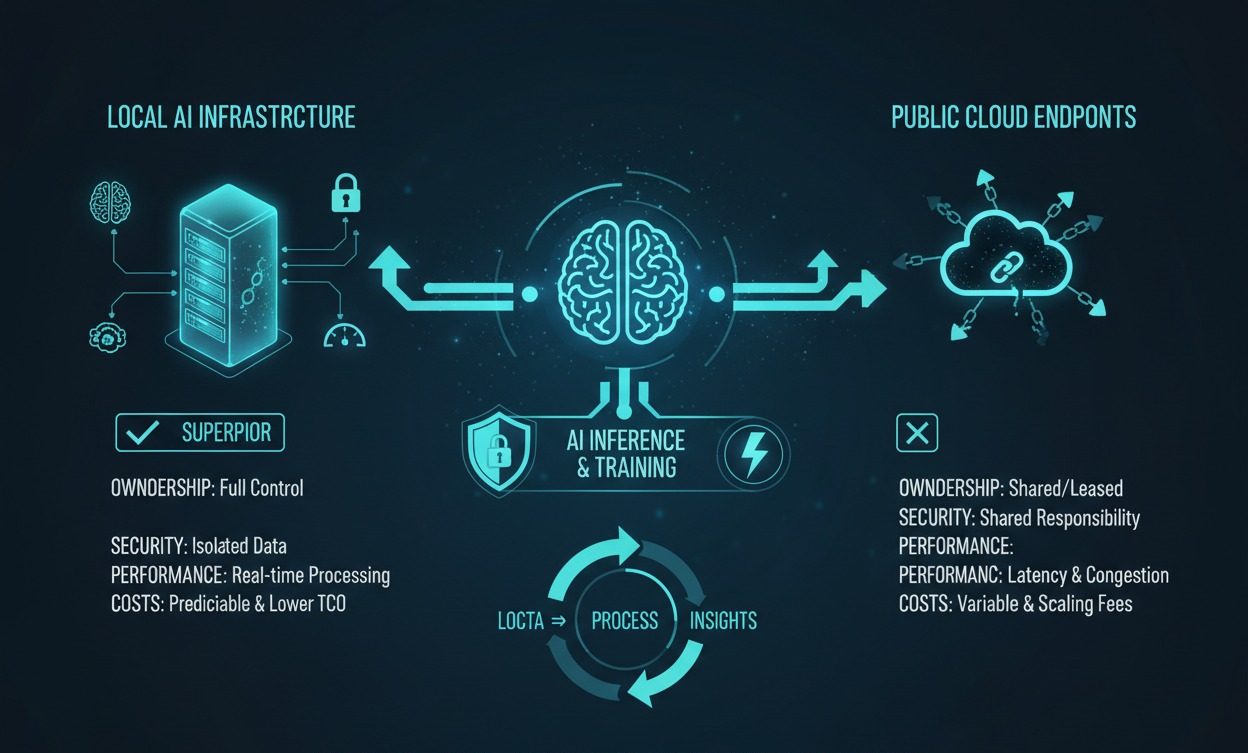
At Embolden Systems, we focus on the underlying plumbing. Cloud APIs are powerful, but they introduce latency, recurring token costs, and strict data boundary vulnerabilities. Moving compute to the edge fundamentally changes how businesses deploy Retrieval-Augmented Generation (RAG) and workflow automation.
The Strategic Advantages of Local Infrastructure
- Absolute Data Sovereignty: When utilizing cloud models, proprietary business data leaves your infrastructure. Local models like Gemma 4 allow enterprises to process sensitive documents, proprietary code, and internal communications entirely on-device or on localized servers. This meets strict compliance guarantees and establishes true digital sovereignty without exposing data to external vendor APIs.
- Zero-Latency Agentic Workflows: Agentic AI requires multi-step planning, autonomous action, and rapid iteration. Sending constant requests to a cloud server creates an unacceptable latency bottleneck. Locally hosted models execute reasoning loops and tool-calling instantly, enabling workflows to operate in real-time.
- Uncapped Scalability and Cost Control: Cloud AI operates on a pay-per-token model, meaning operational costs scale linearly with usage. By self-hosting open models (utilizing architectures like Gemma 4’s 31B Dense or 26B Mixture-of-Experts), businesses convert variable OPEX into fixed infrastructure costs. This allows for unlimited internal querying without unpredictable budget overruns.
- Offline and Air-Gapped Reliability: Connectivity is not guaranteed in all environments. Models deployed via frameworks like Google AI Edge operate fully offline. For mission-critical deployments, localized AI ensures your customized data retrieval systems function regardless of external internet friction, CAPTCHA blocks, or vendor outages.
The Technical Reality of Gemma 4 According to the official Gemma 4 documentation, Google’s deployment highlights the maturity of local AI. It is natively multimodal, capable of processing images, audio, and up to a 256K context window directly on consumer and enterprise hardware. By offering multiple sizes (from the mobile-targeted Effective 2B up to 31B parameters), it provides the exact architecture needed for specific hardware constraints, proving that heavy cloud compute is no longer a strict prerequisite for high-fidelity outputs.
The Embolden Systems Standard Integrating AI into your business is not a creative exercise; it is an infrastructure project. Preparing for local LLMs requires rigorous Generative Engine Optimization (GEO). This means structuring your unstructured data, deploying robust Schema markup, and building clean JSON-LD “Atomic Answer Libraries” that models can confidently extract without hallucination.
If your data is not structured for machine readability, no model—cloud or local—will retrieve it accurately. Embolden Systems builds the technical layer that allows these models to index and understand your business securely and efficiently.